Performance
Da Performance-Optimierungen in der Praxis nur recht selten aber meist an sehr kritischen Stellen einer Software nötig ist, sollte man das Vorgehen vorher an weniger kritischen Testobjekten üben.
Vorbereitung
Kopiere folgenden Beispielcode, welcher die ersten 40 Fibonacci-Zahlen rekursiv berechnet, in eine Datei namens fib.js:
export function fib(n) {
switch (n) {
case 0:
return 0;
case 1:
return 1;
default:
return fib(n - 2) + fib(n - 1);
}
}
for (let i = 0; i < 40; i++) {
const n = fib(i);
console.log(`fib(${i})=${n}`);
}Profiling
Neben einer einigermassen aktuellen Version von Deno von Node.js wird zusätzlich flamebearer benötigt, welches sich folgendermassen installieren lässt:
npm install -g flamebearerFühre dieses Program nun mit Node und dem aktivierten Profiler aus:
node --prof fib.jsDadurch sollte im aktuellen Arbeitsverzeichnis eine Datei mit einem Namen nach dem Muster isolate-*-v8.log entstanden sein. Diese kann nun folgendermassen als sogenannter Flamegraph betrachtet werden: (Wichtig: schreibe unter Windows node.exe statt node!)
node.exe --prof-process --preprocess -j isolate-*-v8.log | flamebearerAnhand dieser Grafik lässt sich der Hot Spot – die Funktion fib – recht einfach ausmachen:
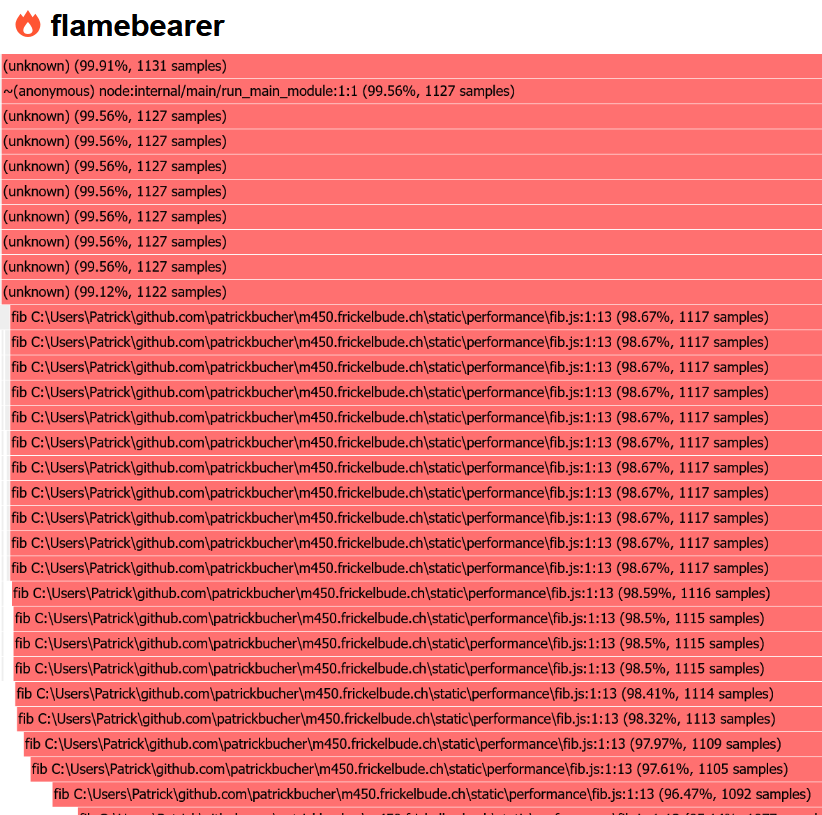
Benchmarking
Eine Funktion muss teilweise sehr oft aufgerufen werden, bis sich ihr Laufzeitverhalten stabilisiert – und dadurch Aussagen über ihre Laufzeiteigenschaften messbar werden. Glücklicherweise verfügt Deno über eine Funktion namens Deno.bench, die analog zu Deno.test funktioniert, aber nicht nur einen Testfall ausführt, sondern auch noch die Performance des ausgeführten Codes misst.
Kopiere folgenden Code in eine Datei namens fib_test.js:
import { assertEquals } from "@std/assert";
import { fib } from "./fib.js";
Deno.bench("fib(30)", () => {
assertEquals(fib(30), 832040);
});Führe diesen Benchmark nun folgendermassen aus:
deno init
deno install
deno bench fib_test.jsDabei sollte eine mit dieser vergleichbaren Ausgabe erfolgen, wobei die Zahlen natürlich abweichen können:
| benchmark | time/iter (avg) | iter/s | (min … max) | p75 | p99 | p995 |
|---|---|---|---|---|---|---|
| fib(30) | 7.6 ms | 132.4 | (7.1 ms … 9.6 ms) | 7.6 ms | 9.6 ms | 9.6 ms |
Optimierung
Ersetze nun die Implementierung von fib durch folgenden iterativen Code:
export function fib(n) {
let a = 0,
b = 1;
for (let i = 0; i < n; i++) {
const c = a + b;
a = b;
b = c;
}
return a;
}Führe erneut ein Profiling und ein Benchmarking durch. Sowohl der Flamegraph als auch die Benchmarking-Ergebnisse sollten neu ein komplett anderes Bild ergeben.
Aufgaben
Die folgenden Aufgaben sollen mit dem Repository performance-tests bearbeitet werden. Erstelle zuerst einen Fork davon und klone diesen. Die Beispiele liegen in JavaScript (und nicht wie üblich in TypeScript) vor, um ein direktes Ausführen mit Deno (Benchmarking) und Node.js (Profiling) zu ermöglichen.
Gehe für jede Aufgabe (Beispiel: foo) folgendermassen vor:
- Betrachte den Code in
foo.jsund versuche seine Funktionsweise zu verstehen. - Betrachte den Testcode in
foo_test.jsund führe ihn mitdeno test foo_test.jsaus. - Leite aus dem Testfall einen Benchmark ab. Verwende hierzu
Deno.benchanstelle vonDeno.test. Achte darauf, keinen trivialen Testfall zu nehmen, sondern einen aufwändigen. Führe den Benchmark anschliessend mitdeno bench foo_test.jsaus. Erweitere die Eingabedaten falls nötig. - Führe ein Profiling für
foo.jsdurch und versuche zu ermitteln, wo sich ein Hot Spot verbirgt. - Erstelle eine alternative Implementierung für die gemessene Funktion unter einem anderen Namen (z.B.
fooOptimized()stattfoo()). - Stelle sicher, dass die bestehenden Testfälle auch für die neue Implementierung funktionieren, indem du einen Testfall für die optimierte Funktion schreibst.
- Wiederhole die Schritte von 3 bis 6, bis du über eine performantere Implementierung verfügst – oder dir die Ideen ausgehen.
Für aussagekräftige Benchmarks müssen möglicherweise die Testdaten erweitert werden. Wichtig: Die Tests müssen immer fehlerfrei durchlaufen!
🟢 Aufgabe 1: Mengen
In sets.js sind zwei Funktionen implementiert:
unique: Gibt ein Array zurück, das alle Elemente aus dem übergebenen Array genau einmal, d.h. ohne Duplikate, enthält.diff: Bildet die Differenz aus den beiden übergebenen Arrays: Die Elemente der ersten Liste, die nicht in der zweiten Liste vorkommen.
Diese beiden Operationen arbeiten auf Arrays. Effizienter wären wohl Implementierungen mithilfe von einem Set. Wichtig: Die Schnittstelle darf nicht geändert werden. Es müssen weiterhin Arrays erwartet und zurückgegeben werden.
🟡 Aufgabe 2: Buchstabenhäufigkeit
In frequency.js ist die Funktion letterFrequency implementiert, welche die Buchstabenhäufigkeit in einem Text zurückgibt. Die Funktion gibt ein Array von Objekten bestehend aus einem Buchstaben und dessen Häufigkeit zurück. Dabei wird nicht zwischen Gross- und Kleinbuchstaben unterschieden.
Die Funktion könnte effizienter implementiert werden. Hier sind zwei Ideen dazu:
- Zähle die Buchstaben mithilfe einer Map (Key: Buchstabe, Value: Buchstabenhäufigkeit) und wandle diese Map am Ende der Funktion in ein Array um.
- Zähle die Buchstaben in einem Array von 26 Elementen, wobei die Häufigkeit von
'a'mit dem Element an Index 0 und'z'mit dem Element an Index 25 gezählt wird. (Tipp: Nutze die Differenz zum Buchstaben'a'um den Array-Index zu finden.)
🔴 Aufgabe 3: Spam-Erkennung
In spam.js ist eine einfache Spam-Erkennung implementiert. Die Funktion classify nimmt einen Text entgegen und berechnet das Verhältnis von verdächtigen Spam-Wörtern zur Gesamtzahl der Wörter im Text. Probiere folgende Optimierungen aus:
- Wird das Programm schneller, wenn der reguläre Ausdruck ausserhalb der Schleife erzeugt wird?
- Gruppiere die Spam-Wörter in einer Map nach ihrem Anfangsbuchstaben (Key: Anfangsbuchstabe, Value: Array von Wörtern mit diesem Anfangsbuchstaben.) Für jedes Wort im Text müssen nun nur noch die Wörter mit dem passenden Anfangsbuchstaben überprüft werden.
⚫ Aufgabe 4: Primzahlen und Primzahl-Faktorisierung
In primes.js sind zwei Funktionen implementiert:
findPrimes: findet die Primzahlen bis zum angegebenenlimit.factorize: zerlegt die angegebene Zahlnin ihre Primfaktoren.
Probiere folgende Optimierungen aus:
- Prüfe in
findPrimesfür die Zahlxnicht für alle Zahlen von 2 bisxauf ihre Teilbarkeit, sondern nur bisx/2. (Durch eine höhere Zahl kannxnicht restlos teilbar sein.) - In
factorizesind nicht alle Primzahlen von 2 bisnnötig. Es genügt die Prüfung bis zur Quadratwurzel vonn(sqrt(n)). Achtung: Istnselbst eine Primzahl, ist diese ihr einziger Primfaktor. - Implementiere das Sieb des Eratosthenes zum Finden der Primzahlen: Zur Prüfung, ob
xeine Primzahl ist, muss diese nicht auf restlose Dividierbarkeit durch alle kleineren Zahlen sondern nur auf restlose Dividierbarkeit durch alle kleineren Primzahlen geprüft werden. - Implementiere eine Klasse
PrimeCache, welche sich alle bisher gefundenen Primzahlen bis zu einer Zahl merkt. (Die Klasse hat eine Eigenschaft für die gefundenen Primzahlen und die bisher höchste geprüfte Zahl.) Du kannstPrimeCacheauch als Iterator implementieren.
Teste die Optimierungen auch mit sehr grossen Zahlen (d.h. im Milliardenbereich).